

引言
在大数据时代,数据科学作为一种新兴的跨学科领域,它的重要性日益显著。在电影产业中,理解观众的喜好、预测票房表现以及优化营销策略等都依赖于对海量电影数据的分析。而大地电影资源作为电影数据的一个重要组成部分,其第二页的数据对于研究者来说尤为重要。本文旨在通过数据科学的方法,对大地电影资源第二页的数据进行可靠性分析,以便更好地理解这些数据的价值和应用潜力。以下是对数据科学解析说明的具体内容。
数据收集
数据的收集是整个分析过程的第一步。对于大地电影资源第二页的数据,我们采用了自动化的网络爬虫技术,从官方网站和相关数据库中抓取数据。这些数据包括电影的基本信息(如标题、导演、演员等),评价数据(如评分、评论数量等),以及票房和放映信息。
数据清洗
由于网络爬虫抓取的数据可能会包含一些错误的信息或者格式不一致的条目,数据清洗成为必要步骤。我们首先识别并去除无效的条目,例如重复的电影记录或错误录入的数据。随后,我们统一数据格式,比如将日期统一为YYYY-MM-DD格式,以及确保评分数据在0-5的范围内。
数据整合与预处理
在清洗完数据后,我们进行数据的整合和预处理工作。这包括将不同来源的数据进行合并,以及处理可能存在的缺失值问题。对于缺失值,我们采取插值或丢弃的方法,这取决于缺失数据的类型和对分析结果的影响程度。
探索性数据分析
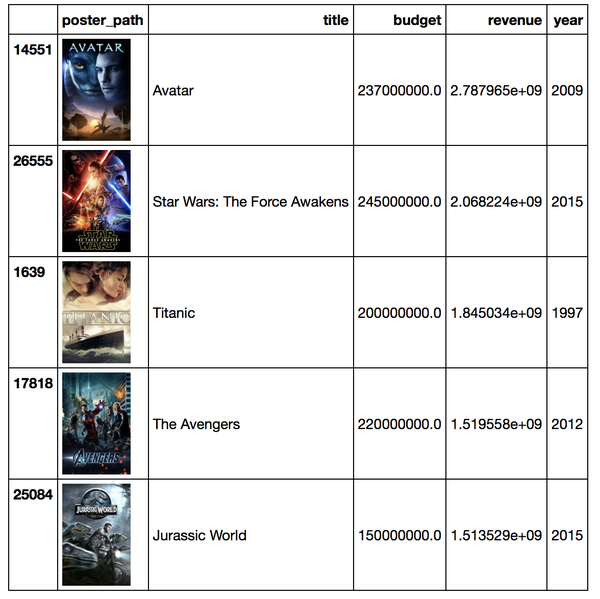
探索性数据分析(EDA)是理解数据特征的重要步骤。我们使用统计图表和可视化工具来分析数据的分布、趋势和关系。例如,我们通过散点图来分析票房与评分之间的关系,通过柱状图来观察不同类型电影的流行程度等。
可靠性分析
接下来,我们将对数据的可靠性进行分析。可靠性是指数据的准确性和一致性。我们通过以下几个方面进行评估:数据来源的可信度、数据收集过程中的误差分析、数据清洗过程中的一致性检查等。
统计分析
统计分析是数据科学中的核心环节。我们采用描述性统计来总结数据的基本特征,如平均值、中位数、标准差等。此外,我们使用推断性统计方法,如假设检验和回归分析,来推断数据之间的关系和趋势。例如,我们可以通过线性回归分析票房和评分之间的相关性。
聚类分析
聚类分析是将数据分组的一种方法,它有助于识别数据中的模式和子群。我们使用k-means聚类算法对电影进行分类,以便更好地理解电影的类型和受众群体。通过聚类分析,我们可以对不同群体的偏好进行更有针对性的研究。
预测模型构建
基于历史数据,我们可以构建预测模型来预测电影的未来票房表现。这通常涉及到机器学习技术,如随机森林或神经网络模型。预测模型的构建需要经过特征选择、模型训练和验证等步骤,最终达到较高的预测准确性。
结果解释与应用
数据科学分析的结果需要被解释,并应用于实际的决策过程中。例如,我们的预测模型结果可以帮助电影制作公司优化预算分配,或者营销团队调整推广策略。此外,通过聚类分析得到的分组信息可以用来定制化广告投放,以提高转化率。

结论与展望
本文通过数据科学的方法对大地电影资源第二页的数据进行了可靠性分析。通过这一系列的数据处理和分析步骤,我们不仅提高了对数据的理解,还为电影产业提供了一系列有价值的洞见和决策支持。未来的研究可以进一步优化分析方法,增加更多的数据来源,以及探索更多高级的数据分析技术,以期获得更深入的洞察。






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...